







Run25K
Comments
Version Detail
SDXL 1.0
NOT MY MODEL
I WILL REMOVE IT IF OWNER ASKS
CREDIT: Koolchh - https://civitai.com/user/Koolchh
AnimeBoysXL
Features
✔️ Good for inference: AnimeBoysXL is a flexible model which is good at generating images of anime boys and males-only content in a wide range of styles.
✔️ Good for training: AnimeBoysXL is suitable for further training, thanks to its neutral style and ability to recognize a great deal of concepts. Feel free to train your own anime boy model/LoRA from AnimeBoysXL.
❌ AnimeBoysXL is not optimized for creating anime girls. Please consider using other models for that purpose.
Inference Guide
Prompt: Use tag-based prompts to describe your subject.
Tag ordering matters. It is highly recommended to structure your prompt with the following templates:
1boy, male focus, character name, series name, anything else you'd like to describe
2boys, male focus, multiple boys, character name(s), series name, anything else you'd like to describe
Append , best quality, amazing quality, best aesthetic, absurdres to the prompt to improve image quality.
(Optional) Append , year YYYY to the prompt to shift the output toward the prevalent style of that year. YYYY is a 4 digit year, e.g. , year 2023
Negative prompt: Choose from one of the following two presets.
Heavy (recommended): lowres, (bad:1.05), text, error, missing, extra, fewer, cropped, jpeg artifacts, worst quality, bad quality, watermark, bad aesthetic, unfinished, chromatic aberration, scan, scan artifacts, 1girl, breasts
Light: lowres, jpeg artifacts, worst quality, watermark, blurry, bad aesthetic, 1girl, breasts
(Optional) Add , realistic, lips, nose to the negative prompt if you need a flat anime-like style face.
VAE: Make sure you're using SDXL VAE.
Sampling method, sampling steps and CFG scale: I find (Euler a, 28, 5) good. You are encouraged to experiment with other settings.
Width and height: 832*1216 for portrait, 1024*1024 for square, and 1216*832 for landscape.
Training Details
AnimeBoysXL is trained from Stable Diffusion XL Base 1.0, on ~516k images.
The following tags are attached to the training data to make it easier to steer toward either more aesthetic or more flexible results.
Quality tags
best quality: score >= 150
amazing quality: score in the range of [100, 150)
great quality: score in the range of [75, 100)
normal quality: score in the range of [0, 75)
bad quality: score in the range of (-5, 0)
worst quality: score <= -5
Aesthetic tags
best aesthetic: score >= 6.675
great aesthetic: score in the range of [6.0, 6.675)
normal aesthetic: score in the range of [5.0, 6.0)
bad aesthetic: score < 5.0
Rating tags
sfw: general
slightly nsfw: sensitive
fairly nsfw: questionable
very nsfw: explicit
Year tags
year YYYY where YYYY is in the range of [2005, 2023].
Training configurations
Hardware: 4 * Nvidia A100 80GB GPUs
Optimizer: AdaFactor
Gradient accumulation steps: 8
Batch size: 4 * 8 * 4 = 128
Learning rates:
8e-6 for U-Net
5.2e-6 for text encoder 1 (CLIP ViT-L)
4.8e-6 for text encoder 2 (OpenCLIP ViT-bigG)
Changes from v1.0
Train with tag ordering.
Add sfw rating tag.
More epochs on the questionable and explicit rating subset.
FP16 mixed-precision training for final epochs.
The above model card is for AnimeBoysXL v2.0. For the model card of v1.0, please refer to here.
Project Permissions
Model reprinted from : https://civitai.com/models/235075?modelVersionId=329911
Reprinted models are for communication and learning purposes only, not for commercial use. Original authors can contact us to transfer the models through our Discord channel --- #claim-models.
Comments
Related Posts









🏂
Oberon














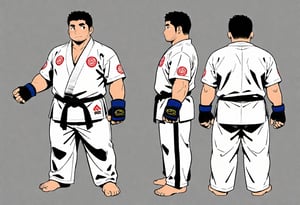
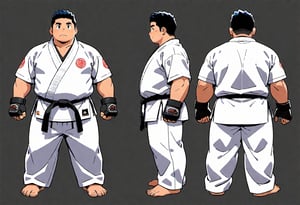
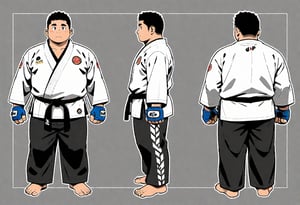





2024-6-22 Character Design
Oberon

























































































































































2024-6-1 Objection
Oberon


















































Reiner Braun
Berthault
Describe the image you want to generate, then press Enter to send.